Graph-driven RAG: Approaches Compared (Part 2)
This post is one in a series exploring the Graph + RAG + LLM equation.
- Motivation & Game Plan
- Basic RAG & RAG with Context Compression (This Post)
- Microsoft-style Graph RAG
- Knowledge Graph RAG
- Summary & Key Take-aways
“Basic” RAG First
The starting point for each of these examples was extracting text from a dump of English language Simplified Wikipedia, using pretty typical recursive text splitting. Learn More

Next we created embeddings for each chunk and uploaded them to a vector store for retrieval. We did this with Databricks’ slick “Delta Sync” feature, so it happens in a single step. Learn More
from databricks.vector_search.client import VectorSearchClient
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name=vector_endpoint,
source_table_name=f"""{schema}.{table_name}""",
index_name=f"""{schema}.{table_name}_index""",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="content",
embedding_model_endpoint_name="databricks-bge-large-en"
)To tie this index into LangChain, we create a simple retriever.
from langchain.vectorstores import DatabricksVectorSearch
from langchain.embeddings import DatabricksEmbeddings
embedding_model = DatabricksEmbeddings(endpoint="databricks-bge-large-en")
vsc = VectorSearchClient()
vs_index = vsc.get_index(
endpoint_name=vector_endpoint,
index_name=f"""{schema}.{table_name}_index"""
)
vectorstore = DatabricksVectorSearch(
vs_index,
text_column="content"
).as_retriever(search_kwargs={"k": 50})Now put it all together with a simple LangChain chain.
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_community.chat_models import ChatDatabricks
prompt = hub.pull('rlm/rag-prompt')
chat_model = ChatDatabricks(
endpoint="databricks-dbrx-instruct",
temperature=0.1
)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": vectorstore | format_docs, "question": RunnablePassthrough()}
| prompt
| chat_model
| StrOutputParser()
)
All that’s left now is to invoke the chain on our sample query, and see what we get.
rag_chain.invoke(user_query)‘A penguin is a flightless bird that lives in the Southern Hemisphere, mostly in Antarctica. They are adapted to live in the water and on land. Penguins have a streamlined body, wings that have become flippers, and a scale-like feathers that help them swim. They eat krill, fish, and squid. Penguins are social animals and live in colonies. They lay one or two eggs at a time and take turns keeping them warm. Penguins are known for their waddling walk and their ability to slide on their bellies across the ice. There are 18 species of penguins, and they vary in size from the little penguin, which is about 16 inches tall, to the emperor penguin, which can be up to 3 feet tall. Penguins are popular animals and are often kept in zoos and aquariums. They are also studied by scientists to learn about their behavior, ecology, and evolution.’
That is…not great.
You may have noticed above we hard-coded the vector retriever to pull 50 documents. This was the most I could reliably fit into the DBRX context window, highlighting a classic RAG issue: If the most “likely” looking documents (according to semantic matching in the vector store) don’t contain the fact the question demands, that fact won’t be in the answer. There are newer models with larger windows, but those models are expensive to run.

RAG with Compression
A common upgrade to basic RAG is Context Compression. The strategy here is to take an initial (larger) pass of documents from the vector store, and then pre-process them by asking an LLM to confirm that they’re relevant to the question at hand. Depending on the implementation details, the large list of documents is either simply filtered into a smaller list, or the first-pass LLM extracts the most important facts and builds new, more valuable documents. Learn More.
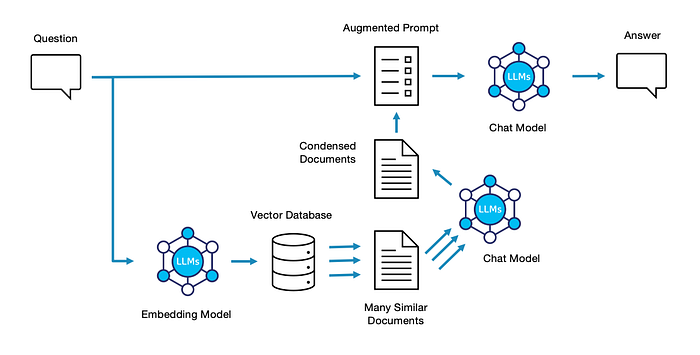
This is a pretty simple modification.
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
compressor = LLMChainExtractor.from_llm(chat_model)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=vectorstore)
rag_chain = (
{"context": compression_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| chat_model
| StrOutputParser()
)
What changed? The answer got better, but my Databricks bill got bigger. I modified the vector retriever to return the 500 best documents (recall penguins are mentioned 361 times), which all resulted in a separate assessment by the DBRX model.
‘Penguins typically nest on the ground, often pushing rocks around the nest to protect it from flooding. Some birds, like puffins, dig tunnels in the ground or in cliffs for their nests, but penguins do not typically engage in this behavior.’
A little better?
Up Next:
Part 3 — Microsoft-style Graph RAG
