Graph-driven RAG: Approaches Compared (Part 3)
This post is one in a series exploring the Graph + RAG + LLM equation.
- Motivation & Game Plan
- Basic RAG & RAG with Context Compression
- Microsoft-style Graph RAG (This Post)
- Knowledge Graph RAG
- Summary & Key Take-aways
Microsoft-type Graph RAG
This approach has several critical components.
- Entity Extraction
Here, we are using an LLM to pull individual “facts” out of the source data. Called “triples”, these facts consist of Subject, Predicate and Object. With the latest extraction techniques via LLM, this process also blends a first pass at categorization.

For example, the sentence “Ryan likes graphs.” might generate the triple (“Ryan (a person)”, “likes”, “graphs (a data structure)”)
Building on the text chunks we created above for Basic RAG, we create our graph with a LangChain transformer.
from langchain_experimental.graph_transformers import LLMGraphTransformer
llm_transformer = LLMGraphTransformer(
llm=chat_model,
node_properties=False,
relationship_properties=False
)There is a lot to say about different methods for initially extracting graph data from text. We’ll keep it simple for now, and take it (much) further in a future post. Generally speaking, though, we feed each document chunk to the transformer we just created and receive a GraphDocument in return.
graph_doc = llm_transformer.convert_to_graph_documents([doc])The resulting GraphDocuments give us a list of “nodes” representing the Subjects and Objects discussed above, and a list of “relationships” representing the full Subject/Predicate/Object connection ultimately used to create edges between nodes in the knowledge graph.
The nodes from a randomly chosen GraphDocument.
nodes=[Node(id=’Animals’, type=’Living_Thing’), Node(id=’Geometry’, type=’Subject’), Node(id=’father’, type=’Sound’), Node(id=’æ’, type=’Sound’), Node(id=’Argon’, type=’Gas’), Node(id=’Algebra’, type=’Subject’), Node(id=’The letter A’, type=’Letter’), Node(id=’Air’, type=’Substance’), Node(id=’Plants’, type=’Living_Thing’), Node(id=’ace’, type=’Sound’), Node(id=’Nitrogen’, type=’Gas’), Node(id=’A’, type=’Letter’), Node(id=’Carbon Dioxide’, type=’Gas’), Node(id=’Oxygen’, type=’Gas’), Node(id=”Sir William Vallance Douglas Hodge’s 5th postulate”, type=’Mathematical_Concept’), Node(id=’Capital A’, type=’Letter’)]
Some relationships from the same document:
relationships=[Relationship(source=Node(id=’The letter A’, type=’Letter’), target=Node(id=’æ’, type=’Sound’), type=’HAS_SOUNDS’), Relationship(source=Node(id=’The letter A’, type=’Letter’), target=Node(id=’father’, type=’Sound’), type=’HAS_SOUNDS’), Relationship(source=Node(id=’The letter A’, type=’Letter’), target=Node(id=’ace’, type=’Sound’), type=’HAS_SOUNDS’), Relationship(source=Node(id=’A’, type=’Letter’), target=Node(id=’Algebra’, type=’Subject’), type=’USED_IN’), …
2. Entity Resolution / De-duplication
Even with careful prompting, there is no guarantee that the same “real world” entity (a subject or object in the triples above) will be identified the same way by the LLM on every extraction. These misalignments come in a few types:
- Syntactic Differences — “R. Oattes” and “Ryan Oattes” are the same person. “Microsoft” and “Microsoft Inc.” are the same company. These can often be handled by non-AI techniques like edit distance analysis.
- Semantic Same-ness — “Sports Team” and “Athletic Club” have a lot in common, but are miles apart in terms of edit distance. This is a much harder problem to solve, but is especially critical in the Microsoft-style RAG context, as at a higher level of summarization we absolutely want to treat these two concepts similarly, and thus need them to be connected in the knowledge graph.
The Microsoft research paper doesn’t pay much attention here, which may be fine for some data sets and some levels of analysis. Other solutions online address the “master data” problem solvable with edit distance solutions like the Levenshtein algorithm. For this implementation, we are using functions from the Kobai SDK to use entity type classification and contextual compression to improve the quality of the knowledge graph. This technique is possible because the Kobai graph database is built on Databricks, so we can scale-up our N:N analysis of entity similarity.
Number of Unique Types
Straight from the LLM Transformer: 32551
After Kobai Compression: 7362
3. Community Detection
Community detection means identifying clusters of nodes that are “related” in the graph. I put “related” in quotes because the term of art is actually “optimized modularity”. In other words, how can I divide this collection of nodes into groups where each node is much more likely to be connected to other nodes IN the group than nodes outside of it.
The Microsoft authors use some of the Leiden algorithm which lends itself towards top-down recursive identification of communities: Finding some large initial communities, then dividing each community into sub-communities, etc. Conceptual example:
top-level: Community of People
next-level: Community of People who Play Sports
next-level: Community of People who Play Baseball
bottom-level: Community of Third Basemen
(In practice, the communities are not going to be so cleanly defined due to the complex nature of graph relationships.)
The implementation we’re using in this example is a little different, as it leverages some additional techniques (described above) to deduplicate nodes. It also contains a mechanism (again from the Kobai SDK) to eliminate layers of communities that are too similar. For this exercise, we are only accepting a lower level of communities if it contains 3x the number of communities in the higher level. This avoids too much redundancy that needs to be summarized below.
In the end, we ended up generating three tiers of communities, with counts as follows:
Tier1: 384
Tier2: 1588
Tier3: 5493
4. Community Summarization
To make use of these communities, we must first ask an LLM to summarize them based on the nodes and relationships they contain. We use a prompt like this one.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
class_template = """
#Goal
Your task is to generate a concise but complete report on the provided graph data belonging to the same graph community. The content of this report includes an overview of the community's key entities and relationships.
#Report Structure
The report should include the following sections:
TITLE: Community's name that represents its key entities - title should be short but specific. When possible, include representative named entities in the title.
SUMMARY: Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary that explains the scope of this community, what topics of knowledge it covers, and what sort of questions it would be useful in answering.
DETAILS: Provide condensed information on facts contained within the graph data. Be sure to include all named entities.
{class_info}
Summary:"""
class_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Given an input triples, generate the information summary. No pre-amble.",
),
("human", class_template),
]
)
community_chain = class_prompt | chat_model | StrOutputParser()Into the {class_info} placeholder, we put a structured list of all the nodes and relationships contained in the community, then feed it to the DBRX model.
Let’s look at the first few lines in an example community summary. (I pulled this out of the database by searching for “penguin”. Did I mention they’re also a team mascot?)
Title: Mascots and Their Significance
Summary: This community revolves around mascots and their significance in various contexts. The community includes well-known mascots such as Tux the Penguin, Northern Heights Wildcats, Smokey Bear, Singha, and Puffy. The relationships highlight the roles and functions of these mascots, such as being a mascot for a high school, teaching people about forest fire prevention, and replacing a previous mascot.
Details:
* Tux the Penguin is a mascot.
* Northern Heights Wildcats is the mascot for Northern Heights High School.
* Smokey Bear teaches people about the dangers of forest fires and how to prevent them.
(etc…)
As before in the RAG example, we are taking these summaries, and using Databricks Vectorsearch to embed them and store the resulting vector.

5. Question Execution
Finally, it’s time to ask our question. To start, our vector search retriever is virtually identical to the one used above, but pointing to a new vector index containing summaries, not raw chunks of source text.
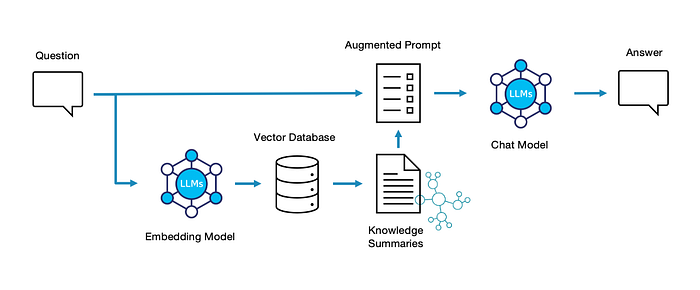
As a first approach, I had the vector store retriever bring back the 5 best community summaries. On first inspection, three of these have promising titles and summaries.
Title: Animal and Plant Life Community
Summary: This community encompasses a diverse range of animal and plant life, including various zoos, aquariums, and botanical gardens. The community covers topics such as animal habitats, species classification, and plant diversity. It would be useful in answering questions related to animal and plant life, conservation efforts, and specific exhibits in various zoos and aquariums.
Title: “Avian Species and Maritime Vessels Community”
Summary: This community revolves around various bird species and their habitats, as well as maritime vessels and their related components. The community includes information on important waterfowl species of the Norwegian Sea, such as the Guillemot, Kittiwake, and Puffin. Additionally, it covers various bird species that inhabit the Khenfiss Lagoon, including the Ruddy Shelduck, Audouin’s Gull, and Marbled Duck. The community also contains information on different types of maritime vessels and their components, such as the cockpit and its location of controls.
Title: Marine and Avian Life: Threats and Conservation
Summary: This community highlights the threats and conservation efforts related to marine and avian life. The key entities include various species such as sharks, cranes, and whales, as well as threats like hunting, habitat destruction, and extreme temperatures. The community also covers conservation measures like banning the capture of certain species and the illegal trade of wildlife.
The other two community summaries were much larger, but for whatever reason the LLM omitted the Title and Summary components I asked for and simply went with a large volume of detailed data. Maybe these two types of communities will be a good combination.
Let’s look at the results.
‘Penguins are found in a variety of habitats, including coastal areas, islands, and open ocean. They are adapted to both cold and temperate climates, with different species found in Antarctica, South America, Africa, and other regions.’
Is this answer better than Basic RAG? Undoubtedly. Context Compressed RAG? It’s a closer comparison, but at the very least it was more efficient use of LLM tokens.
Up Next:
Part 4 — Knowledge Graph RAG
